 Variational Bayesian methods are a great way to get around the computational challenges often associated with Bayesian inference. Because the posterior distribution is often difficult to evaluate, variational methods approximate the true posterior by a parametric distribution with known functional form. The inference algorithm is thus reduced to an optimisation problem whose objective is to tune the parameters of the approximate distribution to match the posterior. Using the popular mean-field approximation, guarantees that the EM-like updates increase the evidence lower bound (ELBO) with every iteration. However, the values of the variational parameters can oscillate if they are strongly coupled by the posterior distribution. The resulting slow convergence is often not obvious from monitoring the ELBO. In this post, we illustrate the problem using a simple linear regression model, and consider alternatives that can help to fit Bayesian models using variational approximations.
Variational Bayesian methods are a great way to get around the computational challenges often associated with Bayesian inference. Because the posterior distribution is often difficult to evaluate, variational methods approximate the true posterior by a parametric distribution with known functional form. The inference algorithm is thus reduced to an optimisation problem whose objective is to tune the parameters of the approximate distribution to match the posterior. Using the popular mean-field approximation, guarantees that the EM-like updates increase the evidence lower bound (ELBO) with every iteration. However, the values of the variational parameters can oscillate if they are strongly coupled by the posterior distribution. The resulting slow convergence is often not obvious from monitoring the ELBO. In this post, we illustrate the problem using a simple linear regression model, and consider alternatives that can help to fit Bayesian models using variational approximations.
Update: This post used
theano, an early machine learning framework that is no longer being actively developed. The code in this post is unlikely to run using a modern machine learning setup.
The standard linear regression problem is defined by
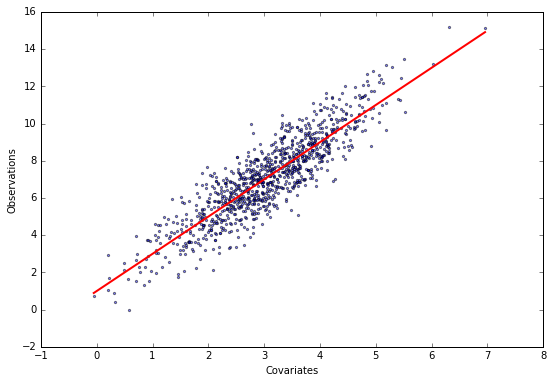
\[y_i = \sum_{j=1}^p X_{ij} \theta_j + \epsilon_i,\]where $y$ is a length-$n$ vector of values we want to predict, $X$ is the $n\times p$ design matrix of $p$ covariates for each observation, $\theta$ are the unknown regression coefficients we need to determine, and $\epsilon_i$ is Gaussian noise. We assume that the noise precision, i.e. the inverse variance, is equal to one. Let’s generate some data.
%matplotlib inline
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import rcParams
rcParams['figure.figsize'] = (9, 6)
# This module contains a few helper functions
from linear_regression import *
# Generate data and plot it
X, y, theta = generate_data(theta=[1, 2])
plot_data(X, y, theta)
# Use same starting position for all optimisers
n, p = X.shape
mu0 = np.random.normal(0, 1, p)
Mean-field variational inference
The log-likelihood is (up to additive constants)
\[\begin{align*} \log P(y\vert X\theta)&= - \frac 12\sum_{i=1}^n\left(y_i-\sum_{j=1}^pX_{ij}\theta_j\right)^2\\ &= -\frac 12\sum_{i=1}^n\left(y_i^2-2y_i\sum_{j=1}^pX_{ij}\theta_j +\sum_{j=k=1}^p X_{ij}\theta_jX_{ik}\theta_k\right). \end{align*}\]We assume flat priors for the regression parameters $\theta$ such that the log-joint distribution $\log P(y\theta\vert X)$ is equal to the log-likelihood up to an additive constant.
Using the mean-field approach, we approximate the true log-posterior $\log P(\theta\vert Xy)$ by a sum of independent terms for each regression coefficient $\log Q(\theta)=\sum_{j=1}^p \log Q_j\left(\theta_j\right)$. The optimal factor for $\theta_j$ is
\[\log Q^*_j\left(\theta_j\right)\doteq\left\langle\log P(y\theta\vert X)\right\rangle_{k\neq j},\]where the subscript $k\neq j$ indicates that the expectation is taken with respect to the posterior approximations $Q_k$ of all regression coefficients $k\neq j$, and $\doteq$ denotes equality up to an additive constant. Substituting the log-likelihood gives
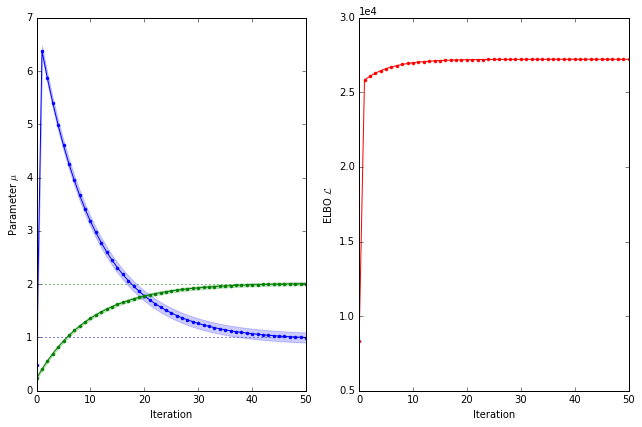
\[\log Q^*_j\left(\theta_j\right)\doteq -\frac 12 \sum_{i=1}^n\left(X_{ij}^2\theta_j^2 - 2 \theta_j X_{ij} \left[y_i-\sum_{k\neq j}X_{ik}\left\langle\theta_k\right\rangle\right]\right)\]such that the optimal factor $Q^*_j$ is a normal distribution with precision $\lambda_j=\sum_{i=1}^nX_{ij}^2$ and mean $\mu_j=\lambda^{-1}_j\sum_{i=1}^n X_{ij} \left[y_i-\sum_{k\neq j}X_{ik}\left\langle\theta_k\right\rangle\right]$. The posterior mean $\mu_j$ agrees with intuition: the best parameter estimate must account for the observations after we have controlled for the effect of all the other covariates. Let’s implement the mean-field inference and plot a trace of the parameter values.
def fit_mean_field(X, y, steps, mu=None):
"""
Fit a simple linear model using a variational mean-field approximation.
"""
# First evaluate the precisions because they do not need to be updated
lmbda = np.sum(X ** 2, axis=0)
# Initialise the parameter values to some random values unless they are provided
if mu is None:
mu = np.random.normal(0, 1, p)
else:
mu = np.copy(mu)
mu_trace = [np.copy(mu)]
# Iteratively apply updates
for step in range(steps):
# Iterate over all parameters
for j in range(p):
# Compute the new posterior mean estimate
mu[j] = np.dot(X[:, j], y - np.dot(X, mu) + X[:, j] * mu[j]) / lmbda[j]
# Store the current estimate
mu_trace.append(np.copy(mu))
return np.asarray(mu_trace)
# Generate a trace of parameter values
trace = fit_mean_field(X, y, 50, mu0)
# Evaluate the ELBO every p-steps
elbos = np.asarray([evaluate_elbo(X, y, mu) for mu in trace[::p]])
# Plot the trace
plot_trace(elbos, trace, theta, X)
pass
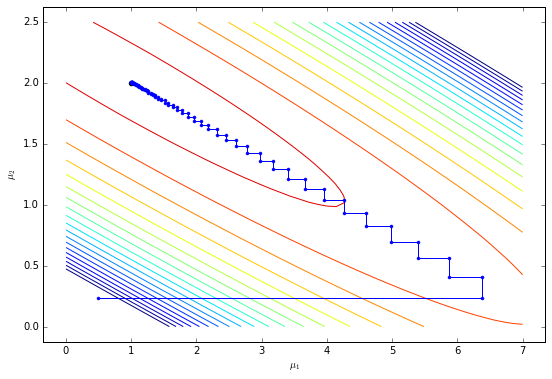
What’s happening? The initial parameter values are not far from the optimal values but they shoot off to strange values before returning to the true parameter values. This isn’t a problem for our small example but can be problematic for larger models. The reason behind this strange behaviour becomes apparent when we consider the trajectory of the parameters $\mu$. Let’s have a look.
plot_trajectory(X, y, trace, theta, levels=np.logspace(4, 4.45, 20))
The algorithm updates each parameter in turn similar to coordinate descent. Because it updates $\mu_1$ first, it takes a step to a location far from the optimal parameter value for $\mu_2$. The algorithm subsequently walks up the ELBO mountain until it reaches the maximum.
In models with thousands of parameters, these update rules lead to oscillations which can persist for a long time. Can we do better?
Variational inference using machine learning frameworks
Machine learning frameworks such as theano and tensorflow are designed to let you define a function symbolically and find its extrema using gradient-based optimisation. The frameworks provide efficient methods for calculating gradients automatically.
Our objective is to maximise the ELBO, which is given by
\[\mathcal{L}=\left\langle\log P(y\theta|X)\right\rangle + H\left[Q\right],\]where $H[Q]$ is the entropy of the approximate distribution. We know that the factors $Q_j$ are normal distributions with mean $\mu_j$ and precision $\lambda_j$ such that
\[\mathcal{L}\left(\mu,\lambda\right)= - \frac 12\sum_{i=1}^n\left(y_i^2-2y_i\sum_{j=1}^pX_{ij}\mu_j +\sum_{j=k=1}^p X_{ij}\mu_jX_{ik}\mu_k + \sum_{j=1}^p X_{ij}^2 \lambda_j^{-1}\right)-\frac 12\sum_{j=1}^p\log\lambda_j.\]Setting the derivative of the ELBO with respect to $\lambda$ to zero, we find
\[\begin{align*} \frac{\partial\mathcal{L}\left(\mu,\lambda\right)}{\partial\lambda_j}&=\frac 12\sum_{i=1}^nX_{ij}^2\lambda^{-2}_j - \frac{\lambda_j^{-1}}{2}=0\\ \therefore \lambda_j&=\sum_{i=1}^n X_{ij}^2, \end{align*}\]which is the same expression we obtained using the mean-field update equations. Substitution yields an expression for the ELBO as a function of the parameters $\mu$ only
\[\mathcal{L}\left(\mu\right)= - \frac 12\sum_{i=1}^n\left(\sum_{j=k=1}^p X_{ij}\mu_jX_{ik}\mu_k-2y_i\sum_{j=1}^pX_{ij}\mu_j\right).\]The derivatives for $\mu$ are more complicated and we will make use of theano to do the heavy lifting for us. We first define a call graph that evaluates the ELBO, and then use gradient ascent to find the maximum.
import theano
import theano.tensor as T
# Define symbolic variables
t_X = T.matrix('X')
t_mu = T.vector('mu')
t_y = T.vector('y')
# Evaluate the predictor
t_predictor = T.dot(t_X, t_mu)
# Evaluate the ELBO
t_elbo = -0.5 * T.dot(t_predictor, t_predictor) + T.dot(t_y, t_predictor)
# Evaluate the gradient
t_grad = theano.grad(t_elbo, t_mu)
# Define a function that returns the objective and gradients
objective = theano.function(inputs=[t_mu, t_X, t_y], outputs=[-t_elbo, -t_grad])
from scipy import optimize
# Minimize the objective function using standard scipy methods
trace = [mu0]
result = optimize.minimize(objective, mu0, (X, y), 'cg', jac=True,
callback=lambda x: trace.append(x))
trace = np.asarray(trace)
# Plot the trajectory
plot_trajectory(X, y, trace, theta, levels=np.logspace(4, 4.45, 20))
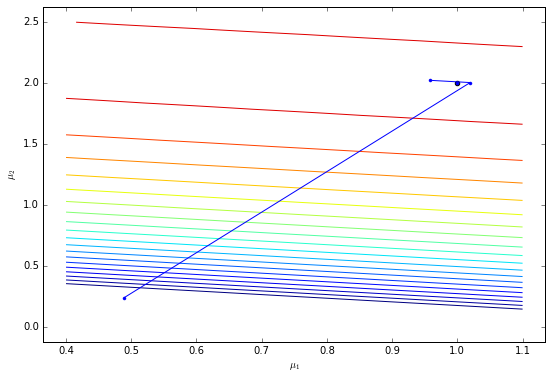
The gradient-based approach only takes two steps to reach the maximum using the conjugate gradient method.
Although the theoretical guarantees provided by the mean-field update equations are appealing, the method can be slow in practice. The methods developed by the machine learning community are able to optimise functions of thousands of parameters, and we should make use of these powerful tools.