-
Fingerprint clustering for content-based audio recognition
Methods and a computer-readable storage device for detecting shared audio content between first audio content information and second audio content information is provided. The methods cluster similar fingerprints to lessen the impact that similar or repetitive sounds have on the final decision, thereby producing a more accurate final decision about whether the first audio content information shares audio content with the second audio content information.
-
Audio fingerprint extraction and audio recognition using said fingerprints
Methods and a computer-readable storage device are disclosed for generating a frequency representation of a query audio file. The frequency representation represents information about at least a number of frequencies within a time range containing a number of time frames of the audio content information and a level associated with each of said frequencies. At least one of area of data points in the frequency representation is selected. A fingerprint for each selected area of data points is generated by applying a trained neural network onto said selected area of data points thereby generating a vector in a metric space. A distance between at least one of the generated query fingerprints and at least one reference fingerprint is calculated using a specified distance metric. A reference audio file having associated reference fingerprints which have produced at least one associated distance satisfying a predetermined threshold is identified.
-
Community Detection In Networks Without Observing Edges
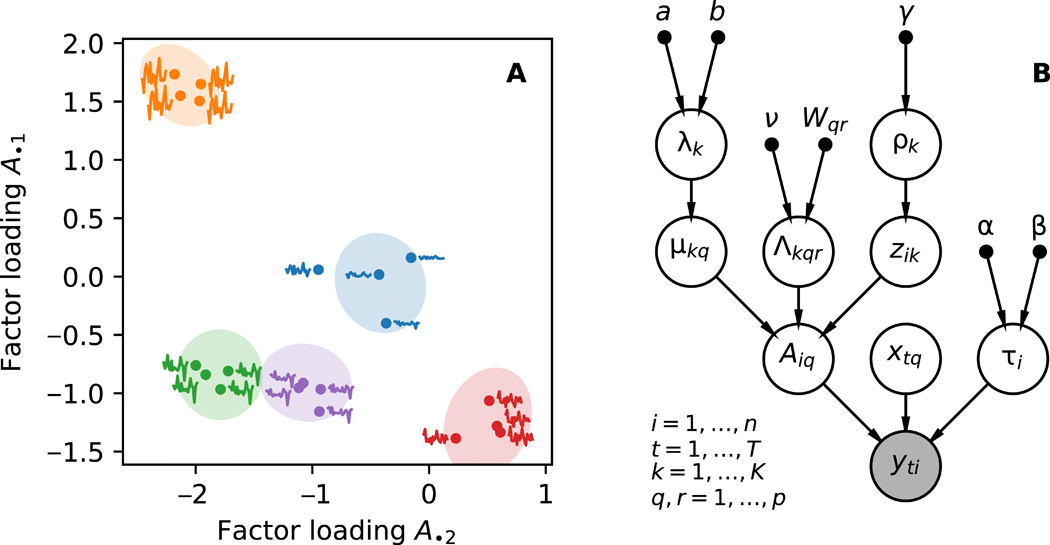 We develop a Bayesian hierarchical model to identify communities of time series. Fitting the model provides an end-to-end community detection algorithm that does not extract information as a sequence of point estimates but propagates uncertainties from the raw data to the community labels. Our approach naturally supports multiscale community detection and the selection of an optimal scale using model comparison. We study the properties of the algorithm using synthetic data and apply it to daily returns of constituents of the S&P100 index and climate data from U.S. cities.
We develop a Bayesian hierarchical model to identify communities of time series. Fitting the model provides an end-to-end community detection algorithm that does not extract information as a sequence of point estimates but propagates uncertainties from the raw data to the community labels. Our approach naturally supports multiscale community detection and the selection of an optimal scale using model comparison. We study the properties of the algorithm using synthetic data and apply it to daily returns of constituents of the S&P100 index and climate data from U.S. cities. -
Precision Identification Of High-Risk Phenotypes And Progression Pathways In Severe Malaria Without Requiring Longitudinal Data
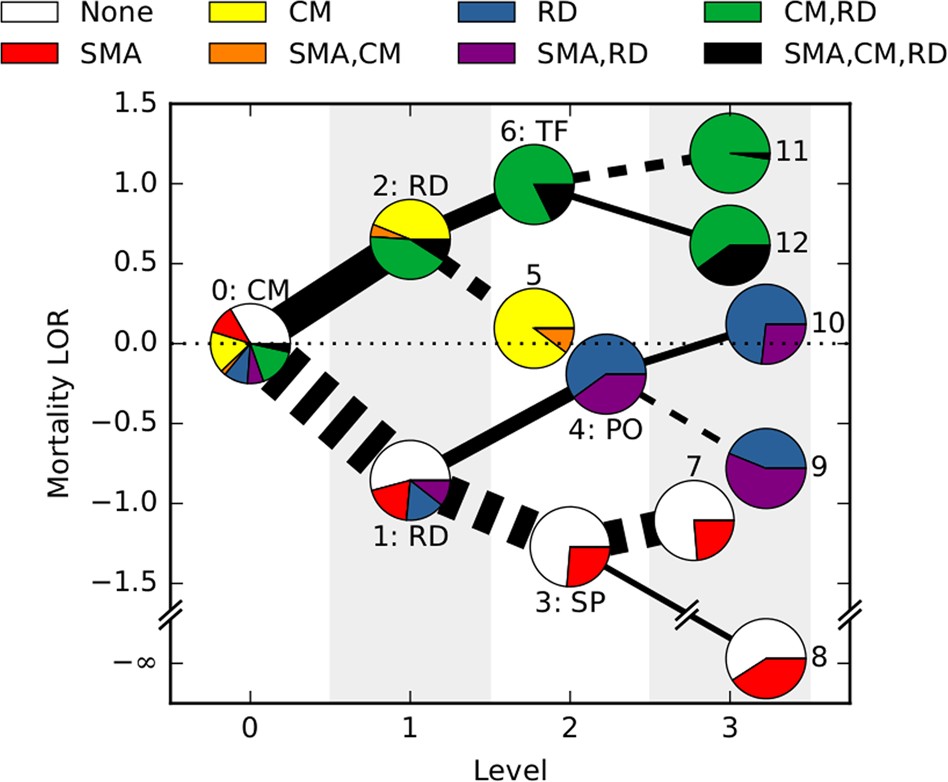 More than 400,000 deaths from severe malaria (SM) are reported every year, mainly in African children. The diversity of clinical presentations associated with SM indicates important differences in disease pathogenesis that require specific treatment, and this clinical heterogeneity of SM remains poorly understood. Here, we apply tools from machine learning and model-based inference to harness large-scale data and dissect the heterogeneity in patterns of clinical features associated with SM in 2904 Gambian children admitted to hospital with malaria. This quantitative analysis reveals features predicting the severity of individual patient outcomes, and the dynamic pathways of SM progression, notably inferred without requiring longitudinal observations. Bayesian inference of these pathways allows us assign quantitative mortality risks to individual patients. By independently surveying expert practitioners, we show that this data-driven approach agrees with and expands the current state of knowledge on malaria progression, while simultaneously providing a data-supported framework for predicting clinical risk.
More than 400,000 deaths from severe malaria (SM) are reported every year, mainly in African children. The diversity of clinical presentations associated with SM indicates important differences in disease pathogenesis that require specific treatment, and this clinical heterogeneity of SM remains poorly understood. Here, we apply tools from machine learning and model-based inference to harness large-scale data and dissect the heterogeneity in patterns of clinical features associated with SM in 2904 Gambian children admitted to hospital with malaria. This quantitative analysis reveals features predicting the severity of individual patient outcomes, and the dynamic pathways of SM progression, notably inferred without requiring longitudinal observations. Bayesian inference of these pathways allows us assign quantitative mortality risks to individual patients. By independently surveying expert practitioners, we show that this data-driven approach agrees with and expands the current state of knowledge on malaria progression, while simultaneously providing a data-supported framework for predicting clinical risk. -
Versioning Jupyter Notebooks With Git
There are a range of approaches to versioning Jupyter notebooks using git (e.g. here, here, and here) by removing any output before adding the notebooks to git. But they typically rely on adding a script to your executable path that can be invoked by a git filter to remove any output.