Latent space approaches to aggregate network data
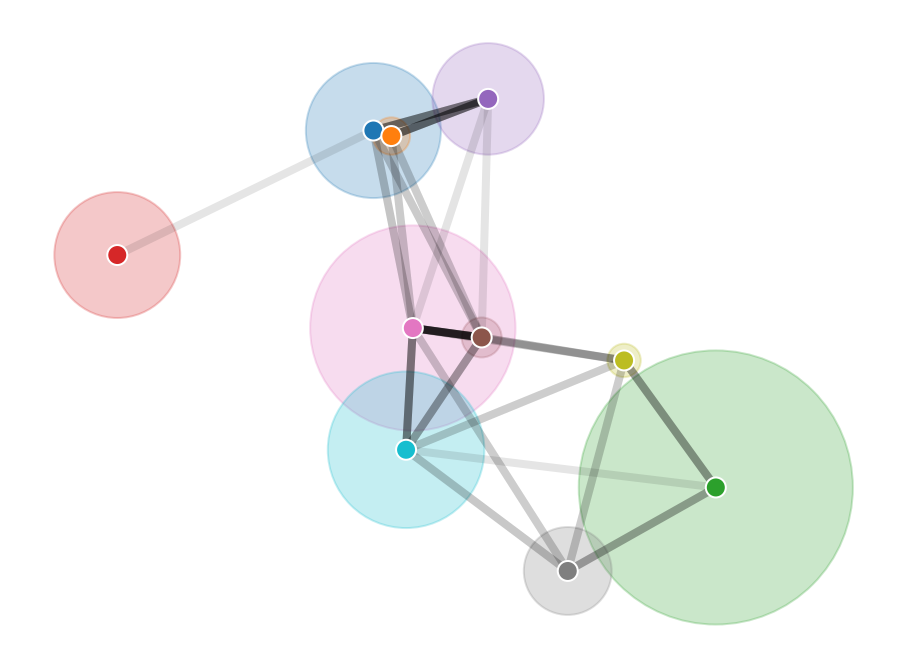 Large-scale network data can pose computational challenges, be expensive to acquire, and compromise the privacy of individuals in social networks. We show that the locations and scales of latent space cluster models can be inferred from the number of connections between groups alone. We demonstrate this modelling approach using synthetic data and apply it to friendships between students collected as part of the Add Health study, eliminating the need for node-level connection data. The method thus protects the privacy of individuals and simplifies data sharing. It also offers performance advantages over node-level latent space models because the computational cost scales with the number of clusters rather than the number of nodes.
Large-scale network data can pose computational challenges, be expensive to acquire, and compromise the privacy of individuals in social networks. We show that the locations and scales of latent space cluster models can be inferred from the number of connections between groups alone. We demonstrate this modelling approach using synthetic data and apply it to friendships between students collected as part of the Add Health study, eliminating the need for node-level connection data. The method thus protects the privacy of individuals and simplifies data sharing. It also offers performance advantages over node-level latent space models because the computational cost scales with the number of clusters rather than the number of nodes.
@article{Hoffmann2023,
title = "Latent space approaches to aggregate network data",
author = "Hoffmann, Till",
journal = "arXiv",
year = "2023",
doi = "10.48550/arXiv.2303.08338",
}