-
Scientific Coding and Data Science with Python and Git
Based on the popular Software Carpentries project, Ariel Vardi, Karen Soenen, and I delivered a two-day workshop for fifty graduate students and research staff at the Woods Hole Oceanographic Institution. Slides from my presentation on using the version control system Git and GitHub for reproducible data science are available here.
-
Approximate Inference for Longitudinal Mechanistic HIV Contact Networks
Network models are increasingly used to study infectious disease spread. Exponential Random Graph models have a history in this area, with scalable inference methods now available. An alternative approach uses mechanistic network models. Mechanistic network models directly capture individual behaviors, making them suitable for studying sexually transmitted diseases. Combining mechanistic models with Approximate Bayesian Computation allows flexible modeling using domain-specific interaction rules among agents, avoiding network model oversimplifications. These models are ideal for longitudinal settings as they explicitly incorporate network evolution over time. We implemented a discrete-time version of a previously published continuous-time model of evolving contact networks for men who have sex with men (MSM) and proposed an ABC-based approximate inference scheme for it. As expected, we found that a two-wave longitudinal study design improves the accuracy of inference compared to a cross-sectional design. However, the gains in precision in collecting data twice, up to 18%, depend on the spacing of the two waves and are sensitive to the choice of summary statistics. In addition to methodological developments, our results inform the design of future longitudinal network studies in sexually transmitted diseases, specifically in terms of what data to collect from participants and when to do so.
-
Network Layout Algorithm With Covariate Smoothing
Network science explores intricate connections among objects, employed in diverse domains like social interactions, fraud detection, and disease spread. Visualization of networks facilitates conceptualizing research questions and forming scientific hypotheses. Networks, as mathematical high-dimensional objects, require dimensionality reduction for (planar) visualization. Visualizing empirical networks present additional challenges. They often contain false positive (spurious) and false negative (missing) edges. Traditional visualization methods don’t account for errors in observation, potentially biasing interpretations. Moreover, contemporary network data includes rich nodal attributes. However, traditional methods neglect these attributes when computing node locations. Our visualization approach aims to leverage nodal attribute richness to compensate for network data limitations. We employ a statistical model estimating the probability of edge connections between nodes based on their covariates. We enhance the Fruchterman-Reingold algorithm to incorporate estimated dyad connection probabilities, allowing practitioners to balance reliance on observed versus estimated edges. We explore optimal smoothing levels, offering a natural way to include relevant nodal information in layouts. Results demonstrate the effectiveness of our method in achieving robust network visualization, providing insights for improved analysis.
-
Digitally Connected Diagnostics Data in the Future of Public Health
 The COVID-19 pandemic has challenged both health care administrators and public health policymakers in unprecedented ways. The dearth of actionable clinical data nationwide impeded prompt evidence-based policymaking and adjustments to health care systems. This highlighted the importance of accessible high-quality real-time clinical data at the local and national level for tackling emerging public health threats. Current methods of data collection for public health are tedious and time-consuming, limiting the speed at which effective measures are determined. Meanwhile, diagnostic companies are increasingly embracing digital technologies, which could put anonymized aggregate diagnostic data, and effective analytics at the heart of health care policy and management. The key to achieving that is—in part—crafting effective public–private partnerships at the federal and international level. Carefully carving out the terms of such partnerships will be crucial to their success. The benefits for governments and their citizens are likely to be worthwhile as public health threats continue to arise, spending remains overstretched, and health care systems overburdened.
The COVID-19 pandemic has challenged both health care administrators and public health policymakers in unprecedented ways. The dearth of actionable clinical data nationwide impeded prompt evidence-based policymaking and adjustments to health care systems. This highlighted the importance of accessible high-quality real-time clinical data at the local and national level for tackling emerging public health threats. Current methods of data collection for public health are tedious and time-consuming, limiting the speed at which effective measures are determined. Meanwhile, diagnostic companies are increasingly embracing digital technologies, which could put anonymized aggregate diagnostic data, and effective analytics at the heart of health care policy and management. The key to achieving that is—in part—crafting effective public–private partnerships at the federal and international level. Carefully carving out the terms of such partnerships will be crucial to their success. The benefits for governments and their citizens are likely to be worthwhile as public health threats continue to arise, spending remains overstretched, and health care systems overburdened. -
Faecal shedding models for SARS-CoV-2 RNA among hospitalised patients and implications for wastewater-based epidemiology
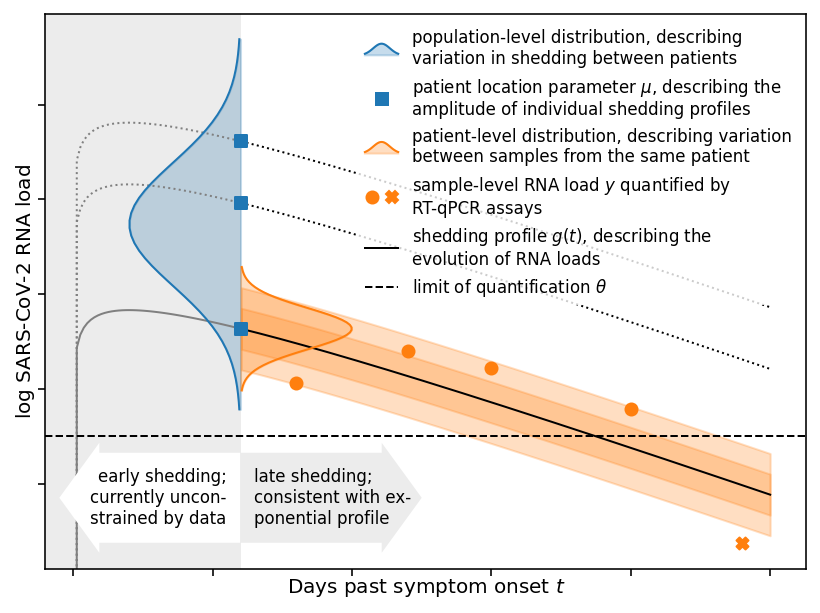 The concentration of SARS-CoV-2 RNA in faeces is not well characterised, posing challenges for quantitative wastewater-based epidemiology (WBE). We developed hierarchical models for faecal RNA shedding and fitted them to data from six studies. A mean concentration of 1.9×10⁶ mL⁻¹ (2.3×10⁵–2.0×10⁸ 95% credible interval) was found among unvaccinated inpatients, not considering differences in shedding between viral variants. Limits of quantification could account for negative samples based on Bayesian model comparison. Inpatients represented the tail of the shedding profile with a half-life of 34 hours (28–43 95% credible interval), suggesting that WBE can be a leading indicator for clinical presentation. Shedding among inpatients could not explain the high RNA concentrations found in wastewater, consistent with more abundant shedding during the early infection course.
The concentration of SARS-CoV-2 RNA in faeces is not well characterised, posing challenges for quantitative wastewater-based epidemiology (WBE). We developed hierarchical models for faecal RNA shedding and fitted them to data from six studies. A mean concentration of 1.9×10⁶ mL⁻¹ (2.3×10⁵–2.0×10⁸ 95% credible interval) was found among unvaccinated inpatients, not considering differences in shedding between viral variants. Limits of quantification could account for negative samples based on Bayesian model comparison. Inpatients represented the tail of the shedding profile with a half-life of 34 hours (28–43 95% credible interval), suggesting that WBE can be a leading indicator for clinical presentation. Shedding among inpatients could not explain the high RNA concentrations found in wastewater, consistent with more abundant shedding during the early infection course.